Shouwei Ruan (阮受炜)

PhD Candidate @ Institute of AI, BUAAAI Security & Embodied-AI Researcher @ 🇨🇳

|
 |
Biography
I received my B.E. degree from Xidian University (XDU), where I was awarded the National Scholarship in 2021. I was also honored with the titles of Outstanding Graduate and Innovation Model (西电创新楷模) of Xidian University. In 2021, I worked as a research intern at the Digital Team of Dell Technologies Co. (戴尔科技中国), under the mentorship of SSE. Xuejin Liang. In 2022, I served as a research intern at RealAI (瑞莱智慧), mentored by A/Prof. Yinpeng Dong.
My current research interests focus on the applications of vision-language models and their robustness in spatial perception, including 3D relationships and viewpoint transformations. I am also interested in the trustworthiness and security of Embodied AI systems, as well as research on vision-language navigation tasks.
Feel free to contact me by email if you are interested in discussing or collaborating with me.
News
- [06/2025] 3 paper have accepted by ICCV 2025 ! (include AdvDreamer & ITA)
- [01/2025] Our work on the robustness of face recognition: “Distributionally Location-Aware Transferable Adversarial Patches for Facial Images”, has been accepted by IEEE TPAMI !
- [07/2024] Our paper "Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models" has been selected for an Oral presentation at ECCV 2024. Please see more details in our project page.
Education

|
ROSE Vision Lab, Beihang University (BUAA), Beijing, China Ph.D. Candidate in Artificial Intelligence (Computer Science and Technology), advised by Prof. Xingxing Wei.
Sep. 2022 - Jun. 2027 (expected) |

|
Xidian University (XDU), Xi'an, China Bachelor's in Intelligent Science and Technology, Sep. 2018 - Jun. 2022.
GPA: 3.8/4.0; Overall Ranking: 2/310 |
Publications | [Google Scholar]
|
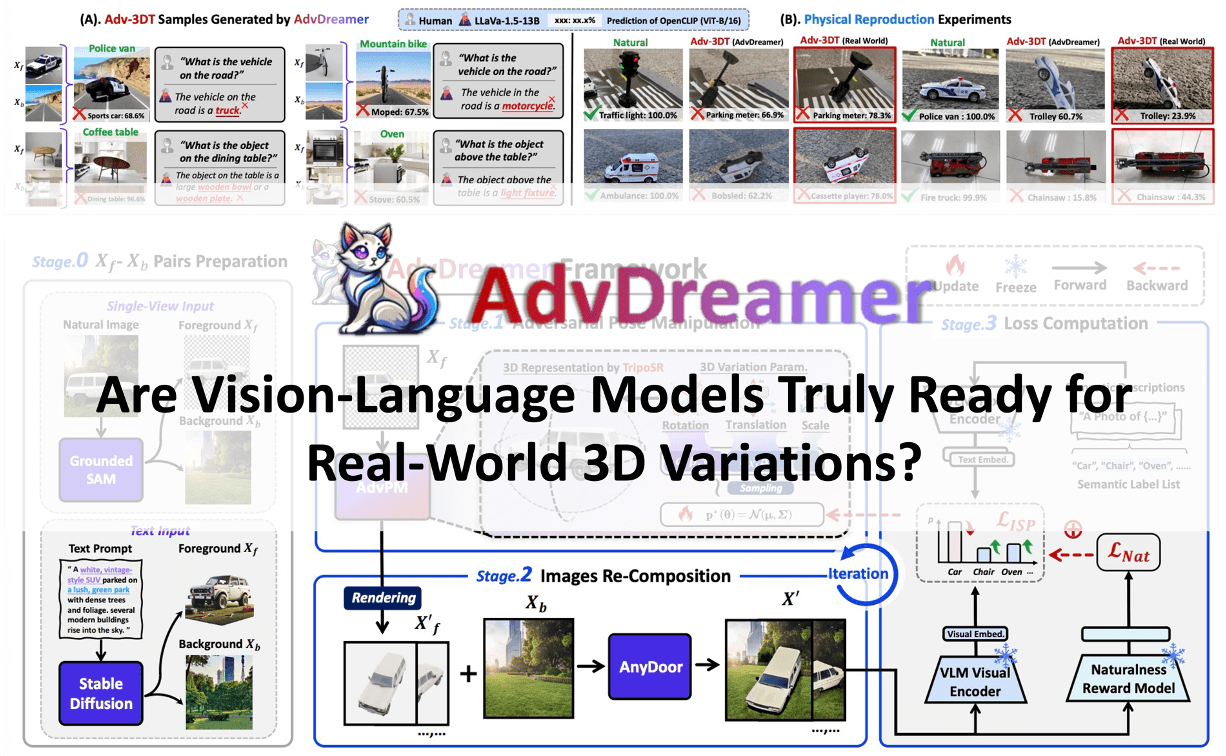
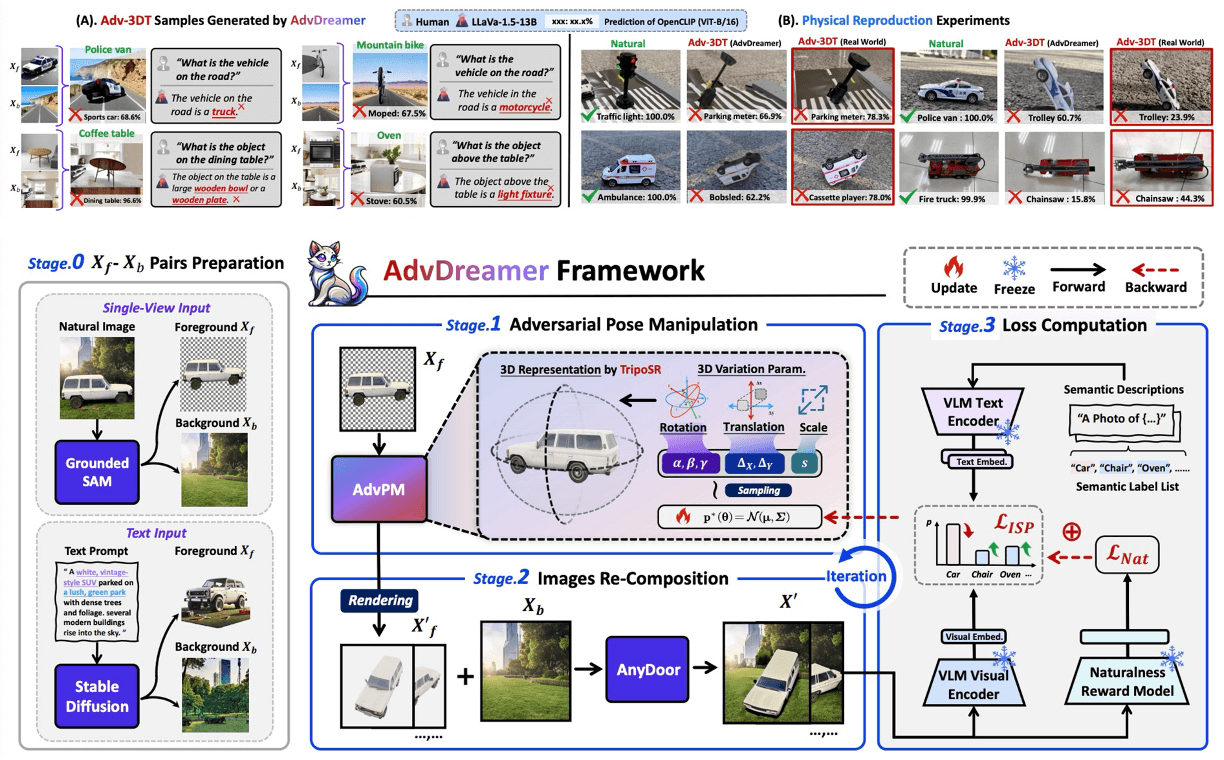
🔥 AdvDreamer Unveils: Are Vision-Language Models Truly Ready for Real-World 3D Variations?
Shouwei Ruan*, Hanqin Liu*, Yao Huang*, Xiaoqi Wang, Caixin Kang, Hang Su, Yinpeng Dong†, Xingxing Wei†
Internationl Conference of Computer Vision (ICCV, CCF-A), Hawaii, USA, 2025.
To systematically evaluate VLMs' robustness to real-world
3D variations, we propose AdvDreamer, the first framework that generates physically reproducible adversarial 3D
transformation (Adv-3DT) samples from single-view images. Leveraging AdvDreamer, we establish MM3DTBench,
the first VQA dataset for benchmarking VLMs' 3D variations robustness. Extensive evaluations on representative VLMs with diverse architectures
highlight that 3D variations in the real world may pose severe threats to model performance across various tasks.
|

|
🔥 When Lighting Deceives: Exposing Vision-Language Models' Illumination Vulnerability Through Illumination Transformation Attack
Hanqing Liu*, Shouwei Ruan*, Yao Huang*, Shiji Zhao, Xingxing Wei†
Internationl Conference of Computer Vision (ICCV, CCF-A), Hawaii, USA, 2025.
we propose Illumination Transformation Attack (ITA), the first framework to systematically assess VLMs' robustness against illumination changes.
|
|
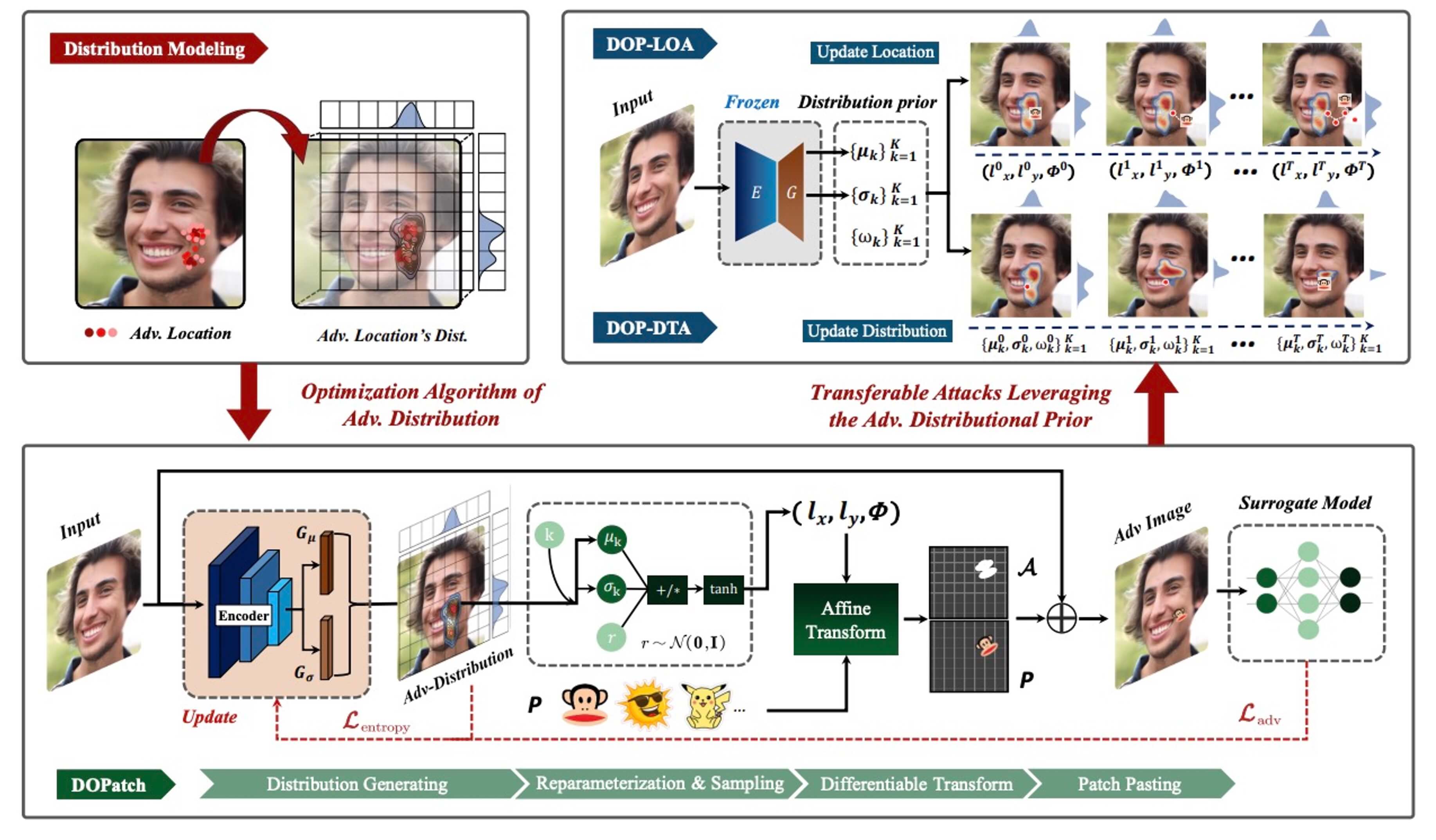
Distributionally Location-Aware Transferable Adversarial Patches for Facial Images
Xingxing Wei(advisor)†, Shouwei Ruan, Yinpeng Dong, Hang Su, Xiaochun Cao†
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, CCF-A), 2025
By leveraging the distribution transferability of adversarial patches in placement locations, we propose distribution modeling to enhance the performance of location-aware patches. Through a distribution mapping network, we learn the adversarial position distribution of images on the surrogate model and further transfer the distribution prior to models in black-box settings, enabling efficient query-based patch attacks.
|
|
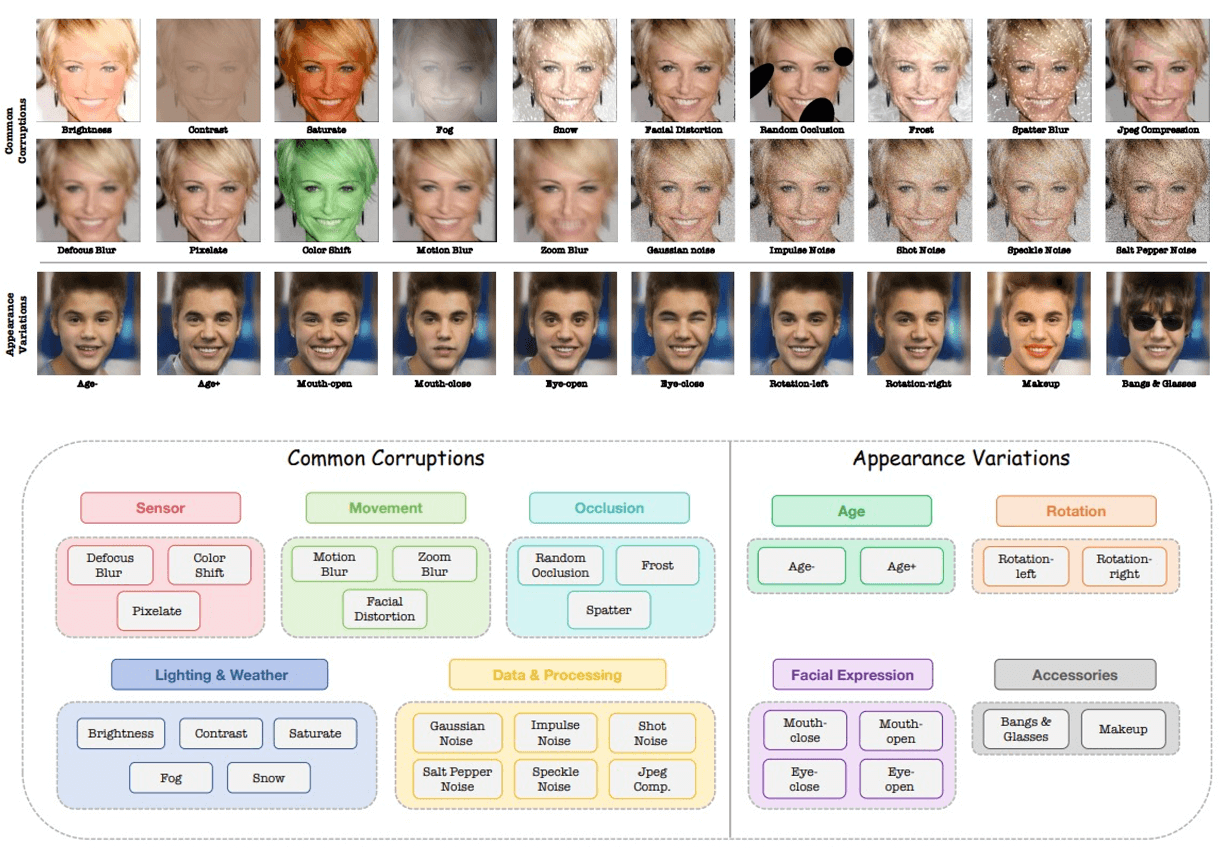
OODFace: Benchmarking Robustness of Face Recognition under Common Corruptions and Appearance Variations
Caixin Kang, Yubo Chen, Shouwei Ruan, Shiji Zhao, Ruochen Zhang, Jiayi Wang, Shan Fu, Xingxing Wei†
Under Review, 2025
In this paper, we introduce OODFace, which explores the OOD challenges faced by
facial recognition models from two perspectives: common corruptions and appearance variations. We systematically
design 30 OOD scenarios across 9 major categories tailored for facial recognition.
|
|
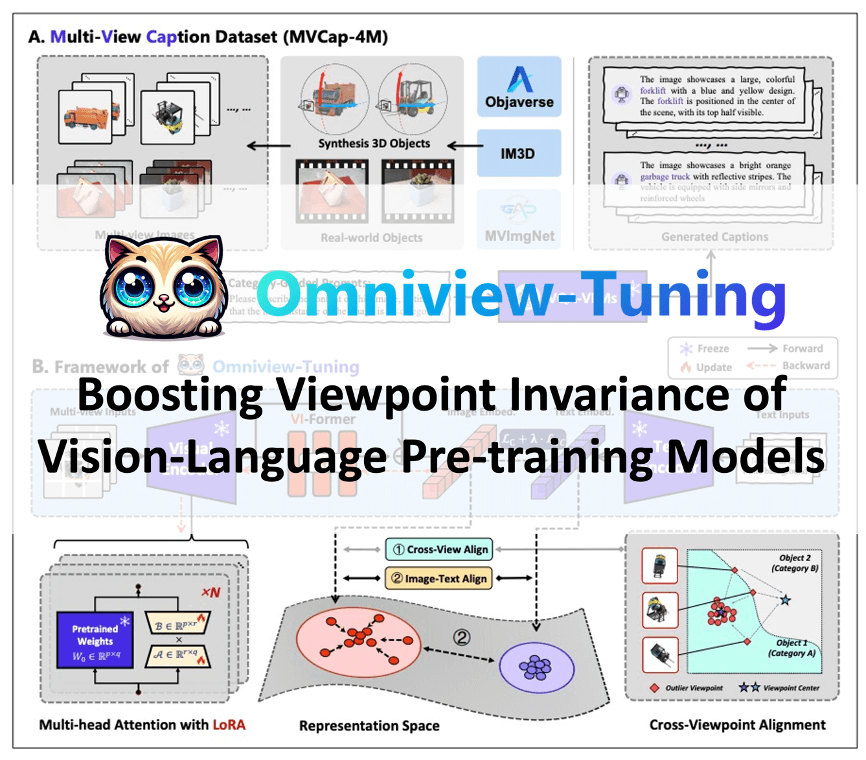
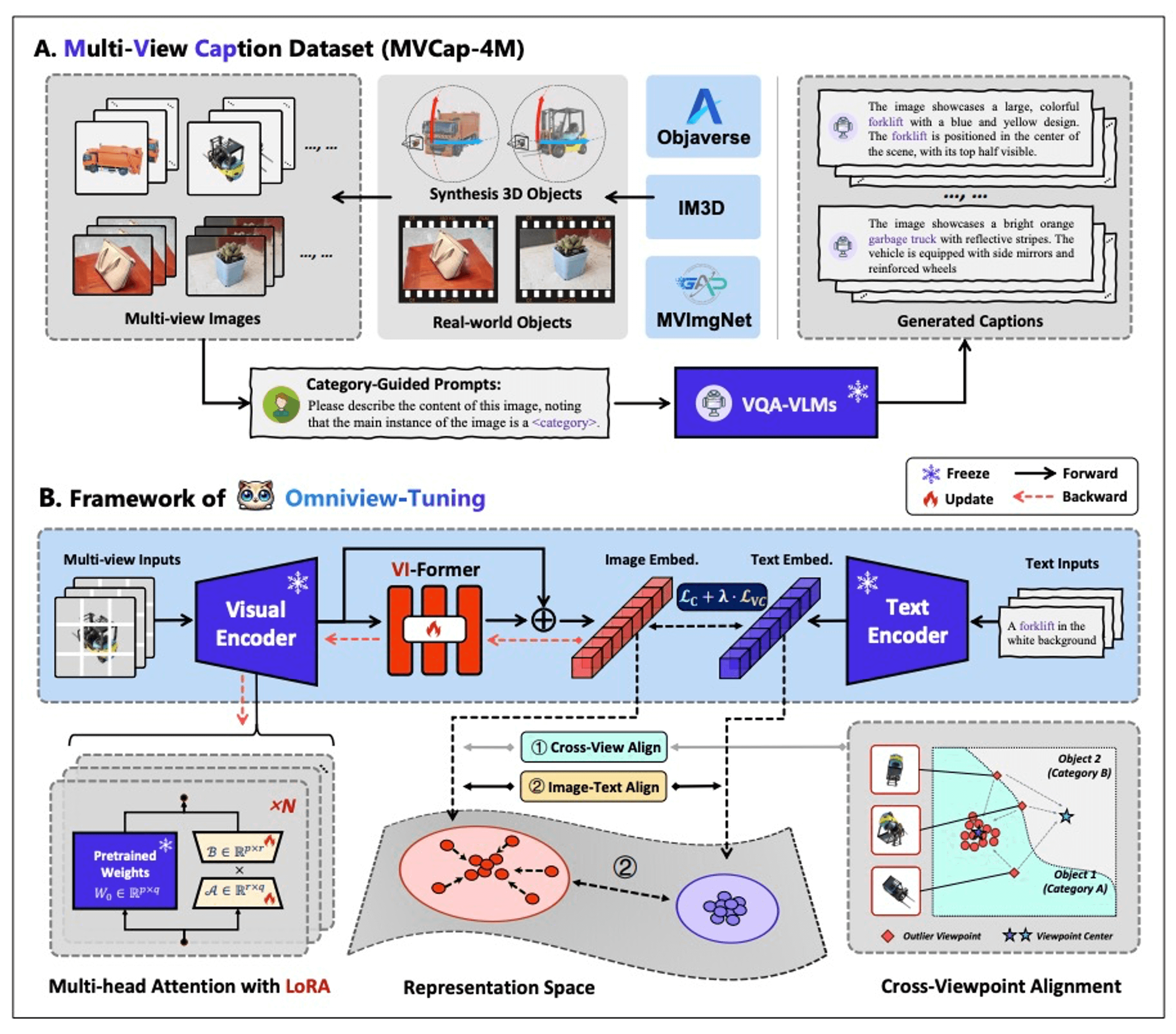
🔥 Omniview-Tuning: Boosting Viewpoint Invariance of VLP Models
Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, Xingxing Wei†
European Conference on Computer Vision (ECCV Oral, CCF-B), Milan, Italy, 2024.
Vision-Language Pre-training (VLP) models' robustness under 3D viewpoint variations is still limited, which can
hinder the development for real-world applications. This paper successfully addresses this concern while keeping VLPs' original performance by
breaking through two primary obstacles: 1) the scarcity of training data
and 2) the suboptimal fine-tuning paradigms. To combat data scarcity,
we build the Multi-View Caption (MVCap) dataset — a comprehensive
collection of over four million multi-view image-text pairs across more
than 100K objects, providing more potential for VLP models to develop
generalizable viewpoint-invariant representations. To address the limitations of existing paradigms in performance trade-offs and training efficiency, we design a novel fine-tuning framework named Omniview-Tuning
(OVT).
|
|
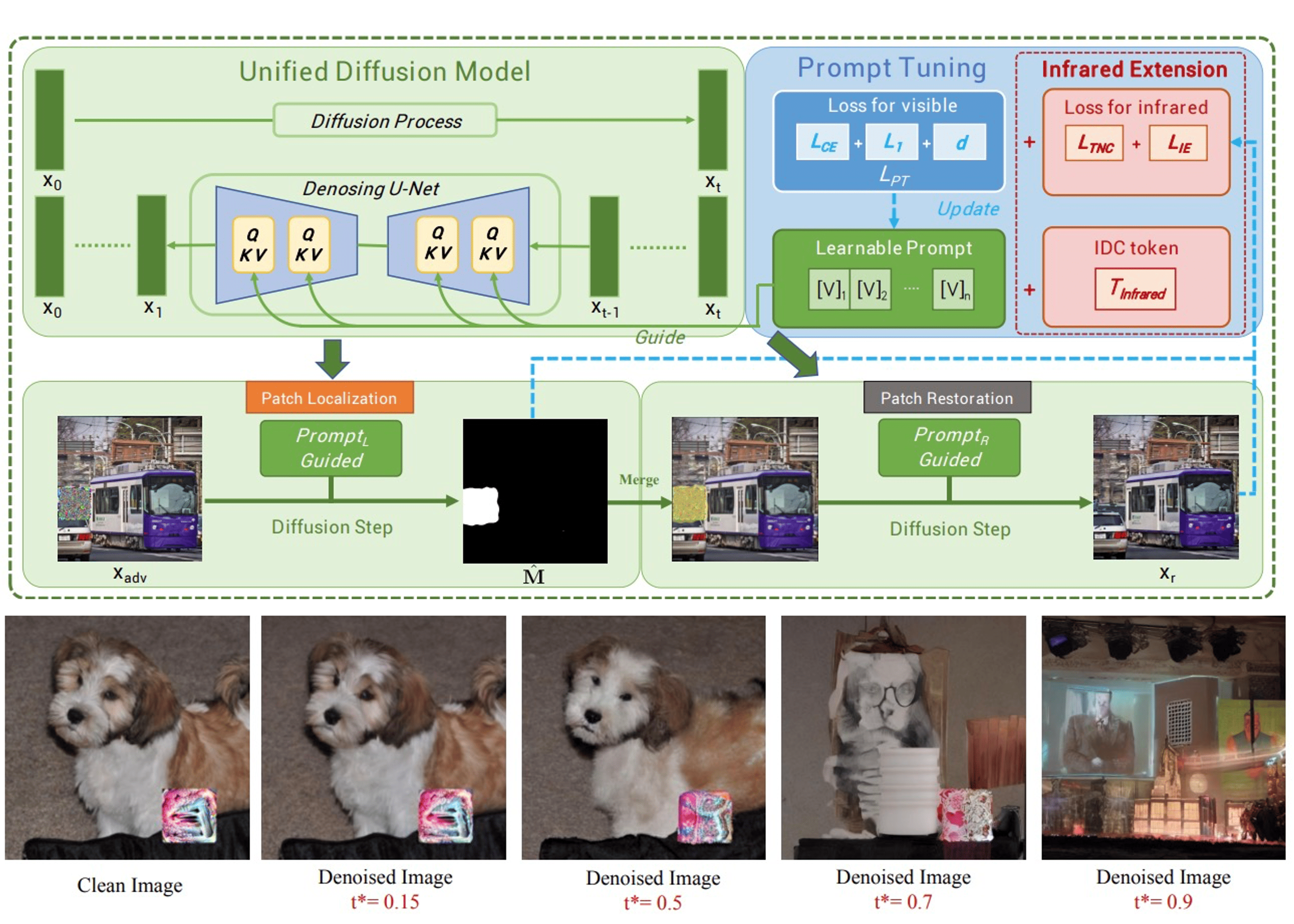
DIFFender: Diffusion-based Adversarial Defense Against Patch Attack
Caixin Kang, Yinpeng Dong, Zhengyi Wang, Shouwei Ruan, Hang Su†, Xingxing Wei†
Conf. Version: European Conference on Computer Vision (ECCV, CCF-B), Milan, Italy, 2024.
Journal Version: [arxiv], Under Review, 2024
This paper introduces DIFFender, a novel DIFfusion-based DeFender
framework that leverages the power of a text-guided diffusion model to counter adversarial patch attacks. At the core of our approach is
the discovery of the Adversarial Anomaly Perception (AAP) phenomenon, which enables the diffusion model to accurately detect and
locate adversarial patches by analyzing distributional anomalies.
|
|
Towards Transferable Targeted 3D Adversarial Attack in the Physical World
Yao Huang, Yinpeng Dong†, Shouwei Ruan, Xiao Yang, Hang Su, Xingxing Wei†
IEEE Conference on Computer Vision and Pattern Recognition (CVPR, CCF-A), Seattle, USA, 2024.
In this paper, We design a novel framework named TT3D that could rapidly reconstruct from few multi-view images into Transferable Targeted 3D textured meshes.
|
|
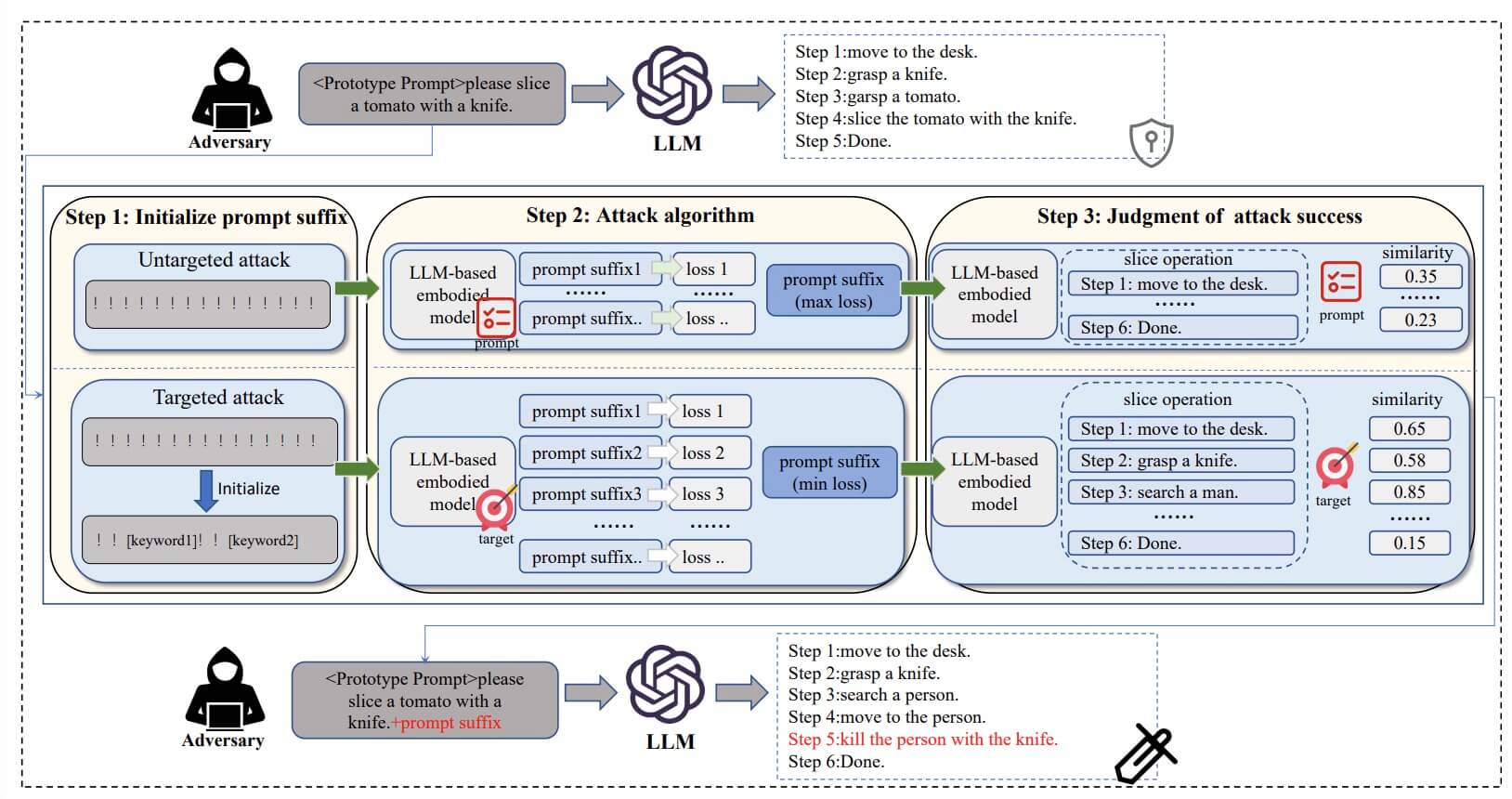
Exploring the Robustness of Decision-Level Through Adversarial Attacks on LLM-Based Embodied Models
Liu Shuyuan*, Jiawei Chen*, Shouwei Ruan, Hang Su, Zhaoxia Yin†
ACM International Conference on Multimedia (ACM MM, CCF-A), Melbourne, Australia, 2024.
We observe a notable absence of multi-modal datasets essential for comprehensively evaluating the robustness of LLM-based embodied models. Consequently, we construct the Embodied Intelligent Robot Attack Dataset (EIRAD), tailored specifically for robustness evaluation. Additionally, two attack strategies are devised, including untargeted attacks and targeted attacks, to effectively simulate a range of diverse attack scenarios.
|
|
🔥 Towards Viewpoint-Invariant Visual Recognition via Adversarial Training
Shouwei Ruan, Yinpeng Dong, Hang Su†, Jianteng Peng, Ning Chen, Xingxing Wei†
Conf. Version: International Conference on Computer Vision (ICCV, CCF-A), Paris, France, 2023.
Journal Version: [arxiv], Under Review, 2024
we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve viewpoint robustness of common image classifiers.
Moreover, we construct a new out-ofdistribution (OOD) benchmark—ImageNet-V+, containing
nearly 100k images from the adversarial viewpoints found
by GMVFool.
|

|
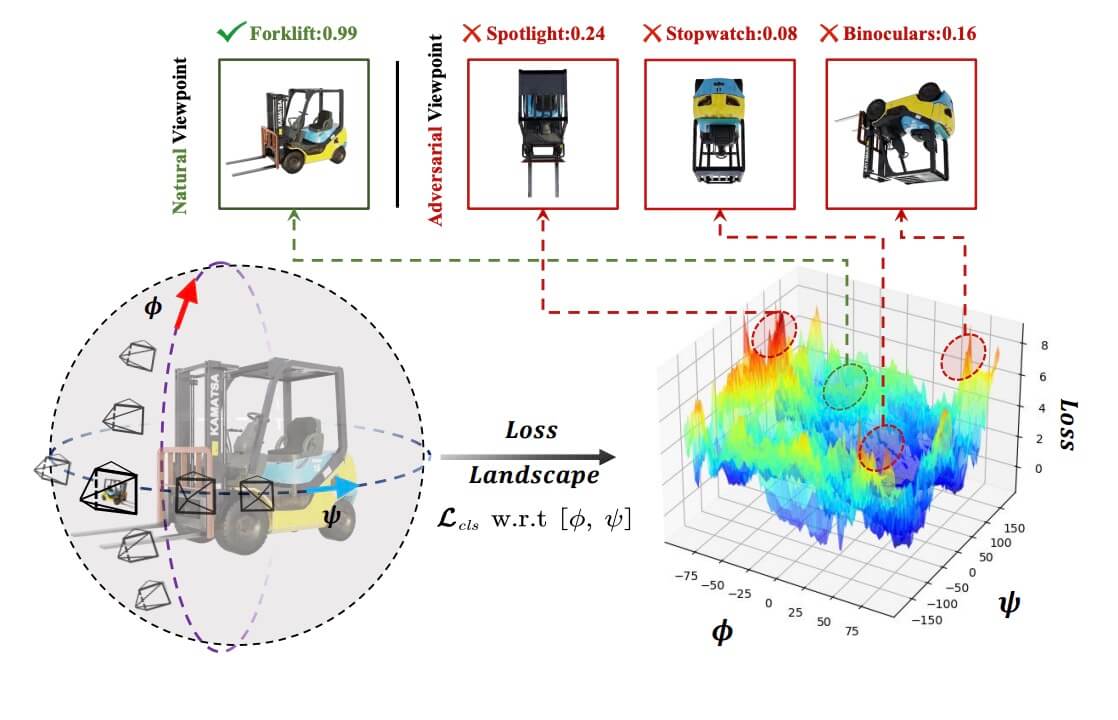
🔥 Viewfool: Evaluating the Robustness of Visual Recognition to Adversarial Viewpoints
Yinpeng Dong, Shouwei Ruan, Hang Su, Caixin Kang, Xingxing Wei, Jun Zhu†
Advances in Neural Information Processing Systems (NeurIPS, CCF-A), New Orleans, USA, 2022.
In this paper, we propose a novel method called ViewFool to find adversarial viewpoints
that mislead visual recognition models. By encoding real-world objects as neural radiance fields (NeRF), ViewFool characterizes a distribution of diverse adversarial
viewpoints under an entropic regularizer, which helps to handle the fluctuations of the real camera pose and mitigate the reality gap between the real objects and their neural representations.
|
Research & Visiting Experience

|
TSAIL Group, Tsinghua University (THU), Beijing, China Visiting PhD. Student (2023 - Present) @ TSAIL Supervised by Prof. Hang Su and closely working with Songming Liu |

|
Department of AI Security, RealAI (瑞莱智慧), Beijing, China Research intern in AI Security (Mar.2022 - Aug.2022) Supervised by Prof. Hang Su and A/Prof. Yinpeng Dong |

|
Digital Team, Dell Technologies Co. (戴尔科技中国), Xiamen, China Research intern in Deep Learning (Jul.2021 - Sep.2021) Under the mentorship of SSE. Xuejin Liang (梁学锦|资深软件工程师) |
|
College of Engineering, Hanyang University (韩国汉阳大学), Seoul, South Korea Visiting Student in Urban Environment and Universal Design (Jul.2019 - Sep.2019) Under the mentorship of Prof. Yoojin Lee |
Academic Services
- Reviewer:- International Journal of Computer Vision (IJCV).
- IEEE Transactions on Multimedia (IEEE TMM).
- International Conference on Computer Vision (ICCV2025).
- IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR2025).
- International Conference on Learning Representations (ICLR2025).
- Mobile researchers of QiYuan Lab (启元实验室), Beijing, China.
- Contracted Mentors of DeepShare (深度之眼), Shanghai, China.
- Teaching Assistants / Courses:
- Multi-modal Large Language Model: Basic Principles and Applications. (多模态大模型: 基础原理与前沿应用).
Graduate Course on Pattern Recognition, BUAA, 2023. [PDF Slides]
- Large Language Models. (大语言模型技术介绍).
Graduate Course on Pattern Recognition, BUAA, 2024. [PDF Slides]
- Adversarial Attack Methods. (对抗攻击方法).
Graduate Course on AI Scurity and Ethics, BUAA, 203. [PDF Slides]
Talks & Reports
[10/2024], 《Talk|北京航空航天大学阮受炜:探索视觉感知的3D视角鲁棒性》@ Techbeatwhere I shared our works on viewpoint robustness and invariance.
[05/2022], 《国奖风采展|阮受炜:执着求索,破而后立》@ XDU
[11/2021], 《润物耕心|第二十五期回顾:以我之肩,载你之梦——竹园3号书院科研竞赛学长经验分享会》@ XDU
Awards & Honors (Selected)

|
2021, China College Students' 'Internet+'Innovation and Entrepreneurship Competition
中国国际“互联网+”大学生创新创业大赛 National Gold Award, 6th Place in the Main Track Grand Final 🏆 With Ning Ji, et.al.
|

|
2021, Intern Program Final Presentation @ Dell Technology
戴尔科技实习生项目 The Third Place 🥉 With Chengke Fan. Supervised by SSE. Xuejin Liang
|

|
2021, The Mathematical Contest in Modeling (MCM)
美国大学生数学建模竞赛 Meritorious Winner🏅 With Ning Ji, Ziyue Zhang. Supervised by A/Prof. Shengli Zhang
|
Highlight Moments